數(shù)字人文的文學(xué)之維 ——相關(guān)軟件介紹與未來軟件展望
來源:文藝報(bào) | 耿弘明 2020年06月29日09:47
數(shù)字人文(Digital Humanity)旨在以數(shù)御文,是一種交叉學(xué)科研究方法,學(xué)者用各類數(shù)字技術(shù)探索人文、社科現(xiàn)象,得出量化結(jié)果并將其進(jìn)行可視化呈現(xiàn)。在世界范圍內(nèi),自羅伯特·布薩(Roberto Busa)編纂托馬斯·阿奎那的著作索引始,數(shù)字人文研究經(jīng)歷了由無到有、由少到多的演變,在英美學(xué)界相關(guān)雜志陸續(xù)誕生,相關(guān)項(xiàng)目層出不窮,名稱和定位也經(jīng)歷了由人文計(jì)算(Humanities computing)到數(shù)字人文的改變。究其大略,其演進(jìn)與計(jì)算機(jī)技術(shù)的發(fā)展呈正相關(guān)關(guān)系,90年代起私人電腦的廣泛普及促進(jìn)了其研究的豐富,近些年人工智能技術(shù)的熱潮,更對(duì)其有推波助瀾之勢(shì)。
在中國,錢鍾書先生獨(dú)具只眼,最早察覺之,授意并助力在社科院啟動(dòng)相關(guān)研究。2000年以后,國內(nèi)相關(guān)研究日漸豐富起來,相關(guān)會(huì)議陸續(xù)召開、有關(guān)公眾號(hào)和雜志陸續(xù)誕生。如今,數(shù)字人文方法在歷史學(xué)界、社會(huì)學(xué)界應(yīng)用較廣,常通過gephi、metlab等數(shù)字工具構(gòu)建社會(huì)網(wǎng)絡(luò),從而理解歷史潮流大勢(shì)走向。而具體到文學(xué)研究領(lǐng)域,這種研究方法的應(yīng)用尚且有限。
談到數(shù)字人文方法在文學(xué)界的應(yīng)用,我們不妨戲仿韋勒克的觀念,將其分為外部研究與內(nèi)部研究。所謂外部研究,指的是通過社會(huì)網(wǎng)絡(luò)分析法,將作家生平、交游、空間走向等可視化,通過作家的外部數(shù)據(jù)分析,可以了解作家的接受程度,以及它與后代讀者、研究者之關(guān)系。外部研究依賴于相關(guān)數(shù)據(jù)的整理工作,例如,布朗大學(xué)的“WOMAN WRITERS PROJECT”項(xiàng)目,致力于收集和整理收集了16世紀(jì)至19世紀(jì)中葉被忽視的女性創(chuàng)作或合著的作品,這類工作也被稱為“數(shù)字檔案館”。
而數(shù)字人文的文學(xué)研究有一個(gè)更有魅惑力的領(lǐng)域——數(shù)字化“內(nèi)部研究”,可以對(duì)于文本進(jìn)行內(nèi)部分析,不妨稱之為“量化新批評(píng)”,也可對(duì)于某些詞匯和語篇的歷史變化進(jìn)行分析,不妨稱之為“量化概念史”,它最終會(huì)幫助發(fā)現(xiàn)一段歷史的文學(xué)內(nèi)部構(gòu)型,與傳統(tǒng)研究法有頗多可對(duì)話之處。毫無疑問的是,此類研究非常依賴于相關(guān)工具的成熟,本文將介紹幾類國外的相關(guān)軟件工具,呈現(xiàn)國外此類研究的樣貌和走勢(shì),以期為國內(nèi)相關(guān)研究提供參照。
“WordHorad”是一款文學(xué)語言分析軟件,它的開發(fā)者將他們的行為稱為“在解鎖語言的寶藏”,的確,通過高度標(biāo)記化的語料數(shù)據(jù),以及對(duì)這些數(shù)據(jù)分布規(guī)律的發(fā)掘,我們可以獲得觀察這些虛構(gòu)文學(xué)文本的另一只眼睛。“WordHoard”主要通過關(guān)鍵詞提取和互相呈現(xiàn)的方法,對(duì)文學(xué)文本進(jìn)行研究,在“WordHoard”的官方示例中,它展示了一些有趣的案例,例如“l(fā)ove”一詞的研究,它在喬叟、莎士比亞等人那里呈現(xiàn)的不同拼寫特點(diǎn),在不同的歷史時(shí)期有著不同的分布規(guī)律,通過對(duì)“l(fā)ove”進(jìn)行統(tǒng)計(jì),研究者得出了很有趣的結(jié)論:在各類敘事文本中,愛被男性說出的次數(shù)多于女性,在喜劇類文本中,被女性說出的次數(shù)則是男性的三倍,這一結(jié)果揭示了“l(fā)ove”的文本秘密,愛要怎么說出口?這非常值得文學(xué)史家的重視和進(jìn)一步分析。
案例還提供了關(guān)于4位大作家的語言統(tǒng)計(jì)表——
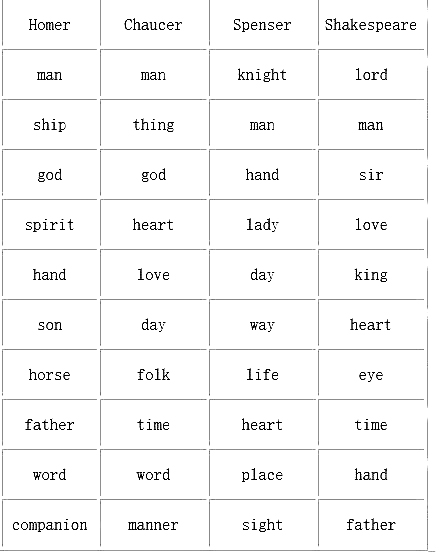
通過這樣的表格可以發(fā)現(xiàn),荷馬、喬叟、斯賓塞、莎士比亞的風(fēng)格與他們所處時(shí)代的變遷得到了一種獨(dú)特的呈現(xiàn),通過主題詞的變遷,我們能夠窺見不同時(shí)代的文學(xué)主題與不同作家的文本主題,達(dá)成對(duì)一位作家語言無意識(shí)的理解。就名詞而言,在莎士比亞的所有文本中,愛是出場(chǎng)率第四高的名詞,只有主(lord)、人(man)和先生(sir)三個(gè)詞出場(chǎng)率高于愛,而其他三位作家所使用的最高頻名詞則沒有愛(love),無論莎士比亞是偉大的愛情謳歌者,還是偉大的愛情質(zhì)疑者,愛都是其一個(gè)重要表現(xiàn)和反思主題。
谷歌是人工智能領(lǐng)域的領(lǐng)頭羊,而谷歌圖書中收錄的大量書籍,谷歌搜索中存在的大量網(wǎng)頁文字?jǐn)?shù)據(jù),以及谷歌學(xué)術(shù)中的學(xué)術(shù)文字記錄,都為構(gòu)建這樣一個(gè)龐大的語料庫有所助益。它出品的在線工具“Google Ngram viewer”主要基于谷歌圖書的語料庫,方便展現(xiàn)不同語詞在歷史上的整體變化。通過輸入想要查找的關(guān)鍵詞,便可以看到在相關(guān)語料中,隨著歷史發(fā)展,相關(guān)詞語的變化趨勢(shì)。例如,筆者將時(shí)間限定為1940-2000年,鍵入孔子、孟子、老子、莊子、朱熹等中國歷代思想家,可以發(fā)現(xiàn),它們歷年在數(shù)據(jù)庫中的權(quán)重變化,這一數(shù)據(jù)顯示,孔子無疑是最有熱度的思想家,與學(xué)者和相關(guān)論者的思想勾連也最為密切。
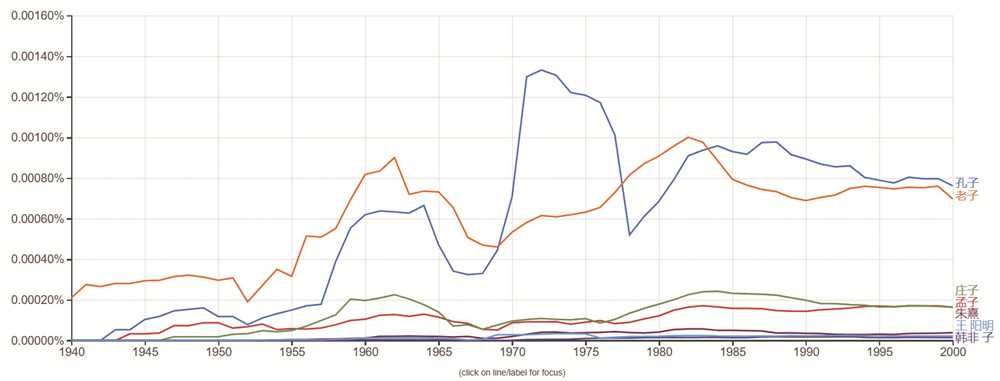
再如,可以選取幾位當(dāng)代作家,如莫言、余華、王朔,觀察自1980年代以來,在紙質(zhì)書數(shù)據(jù)庫中他們的權(quán)重走勢(shì)。
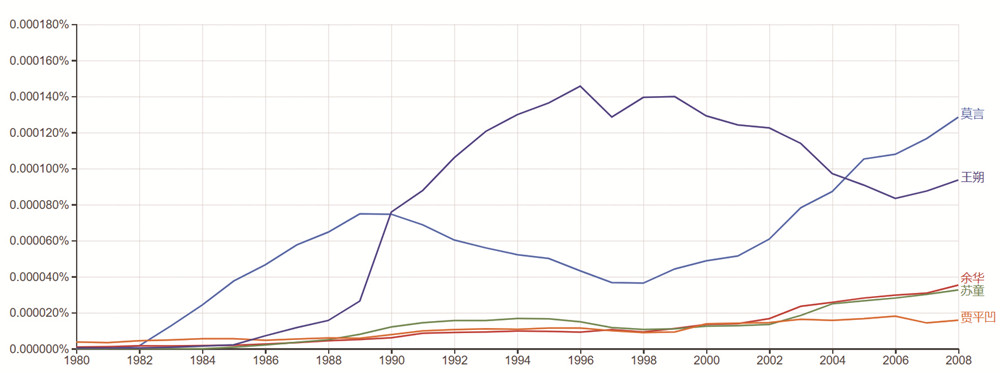
可見,這些走勢(shì)也值得文學(xué)史家的注意,如果加入更多的比較維度,無疑會(huì)誕生更多有趣的研究成果。
21世紀(jì),自人工智能技術(shù)得到了重要突破后,自然語言處理(NLP)相關(guān)技術(shù)得到了突飛猛進(jìn),如今大數(shù)據(jù)、人工智能等關(guān)鍵詞人盡皆知,而機(jī)器翻譯、語音識(shí)別、人機(jī)對(duì)話等功能也在手機(jī)端得到了廣泛的應(yīng)用,我們的日常生活常常與它糾纏為一體。自然語言處理技術(shù)對(duì)文學(xué)產(chǎn)生了一定影響,促生了引發(fā)廣泛爭議的“機(jī)器人寫詩”現(xiàn)象,引得無數(shù)文學(xué)從業(yè)者困惑于詩歌的邊界,也引得諸多哲學(xué)家討論人類與機(jī)器的邊界。另一方面,自然語言處理技術(shù)對(duì)文學(xué)研究也產(chǎn)生了很多介入的可能。
建立在自然語言處理基礎(chǔ)上的相關(guān)研究,為文學(xué)研究提供了新的可能。“NLTK”全稱為"Natural Language Toolkit",是賓夕法尼亞大學(xué)發(fā)布的自然語言處理工具,幾乎是聲名最為響亮的處理工具,它需要通過計(jì)算機(jī)python語言來操作和使用,該模塊中包含了大量的語料資源,如《圣經(jīng)》、莎士比亞的《哈姆雷特》等多部戲劇、簡·奧斯丁的小說、惠特曼的詩集等,除此之外,它也包含路透社的新聞文檔、美國總統(tǒng)的演講集、一些電影劇本原文、網(wǎng)友的網(wǎng)絡(luò)論壇聊天記錄,其文本含量不可謂不豐富,源自不同歷史階段的詞語儲(chǔ)備不可謂不全面。而“NLTK”中的內(nèi)置函數(shù)和功能,則有助于深度挖掘文本的表達(dá)結(jié)構(gòu),細(xì)致探索其語言模式,詳盡勾勒其語言地貌。例如“similiarity”函數(shù)有助于幫助計(jì)算詞匯相似度,“l(fā)en”函數(shù)有助于發(fā)現(xiàn)文本的復(fù)雜程度,“concordance”函數(shù)有助于發(fā)現(xiàn)某些特定詞匯的上下文等等。
在官方相關(guān)示例中,一些獨(dú)特的研究結(jié)果已經(jīng)被呈現(xiàn)出來,例如,在不同時(shí)代的美國總統(tǒng)演講中,總統(tǒng)想強(qiáng)調(diào)的重點(diǎn)自然不同,那么“citizen”和“american”兩詞的使用頻率有什么變化?有關(guān)研究人員對(duì)其進(jìn)行了一種可視化呈現(xiàn)。
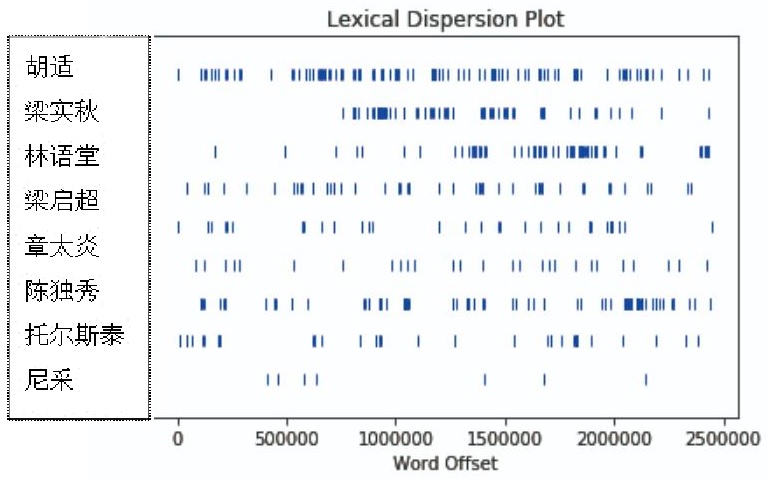
同樣,也可用它對(duì)中文文本進(jìn)行研究,例如,某些特定的人名在作家魯迅的文本中的分布狀況如何呢?筆者采用python中的nltk模塊繪制了如下分布圖。
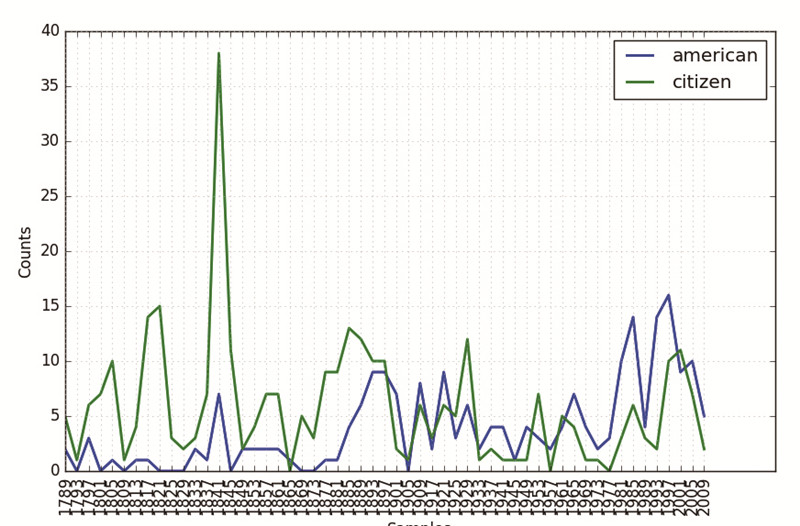
眾所周知,魯迅先生自己的求學(xué)讀書階段,受章太炎、梁啟超、托爾斯泰等影響深遠(yuǎn),之后與梁實(shí)秋、林語堂發(fā)生過學(xué)術(shù)爭論。不過,胡適成了分布最廣泛的人名。
“Gephi”是一款進(jìn)行網(wǎng)絡(luò)分析的軟件,自復(fù)雜科學(xué)成為學(xué)術(shù)熱點(diǎn),復(fù)雜網(wǎng)絡(luò)圖譜的繪制成為諸多學(xué)科中的必備技能,如傳染病網(wǎng)絡(luò)、神經(jīng)網(wǎng)絡(luò)、金融網(wǎng)絡(luò)、物流網(wǎng)絡(luò)等。而“Gephi”可以應(yīng)用于文學(xué)內(nèi)部研究領(lǐng)域,繪制一部作品內(nèi)部的語言網(wǎng)絡(luò)。例如,通過對(duì)魯迅作品中形容詞進(jìn)行統(tǒng)計(jì)分析,可以發(fā)現(xiàn)其內(nèi)部語言網(wǎng)絡(luò)。
不過,目前這些軟件大部分集中于英文處理,基于相對(duì)完備的英文語料庫,同樣也基于西方世界,尤其是美國在計(jì)算機(jī)科學(xué)方面的領(lǐng)軍地位,和西方世界人文社科學(xué)界的前沿視角。而中文語料庫以及建立在其之上的研究板塊,呈現(xiàn)出一種缺失。近些年,作家走走的團(tuán)隊(duì)已經(jīng)致力于開發(fā)中文文本分析的軟件,對(duì)文學(xué)雜志《收獲》中的文學(xué)作品和網(wǎng)絡(luò)文學(xué)進(jìn)行分析,并取得了可觀的成果。不過,更值得期待的是這一領(lǐng)域的成果日益豐富,觀點(diǎn)百花齊放,為傳統(tǒng)文學(xué)史與文論研究提供了另一種參照。
類似的中文文學(xué)文本分析工具還有待豐富。不過,如今自然語言處理技術(shù)的發(fā)展,人工智能的發(fā)展,以及通用人工智能(AGI)的暢想,為這種豐富提供了一種可能,筆者對(duì)這樣的一款文學(xué)通用軟件做出如下暢想——
首先,它能夠進(jìn)行基本的詞頻分析,和建立在詞頻以及權(quán)重分析上的詞語分布研究,通過它,我們可以發(fā)現(xiàn)不同作家和不同時(shí)代的文本差異。例如,20世紀(jì)20年代中國文學(xué)的高頻詞是哪些?與30年代有何不同?京派文學(xué)與海派文學(xué)可以通過這種方式得到量化的區(qū)分嗎?唐宋之爭中的唐詩宋詞,是否存在文本關(guān)鍵詞分布的明顯差異?
其次,建立不同的詞典庫,針對(duì)不同詞性的分布進(jìn)行具體分析,這些包含基本的動(dòng)詞、形容詞、名詞等,也可以通過專門詞典的建立,分析某一類(如文論類,哲學(xué)類詞)的分布。例如,魯迅先生最愛用哪些動(dòng)詞?美學(xué)家朱光潛最喜愛引用哪些人名?當(dāng)代文學(xué)理論和文學(xué)史類教材里哪些概念出現(xiàn)頻率最高?這些都是饒有趣味的文體。
再次,通過基于lstm原理和tensorflow的操作方式,通過情感計(jì)算來探索文本的情感分布奧秘,發(fā)現(xiàn)文本的情感曲線和走勢(shì)圖,窺探不同作家的情緒世界,不同批評(píng)家的情感風(fēng)格,以及某一時(shí)代的讀者群落的精神風(fēng)貌。韓愈散文的情感走向與南朝駢文有何不同?網(wǎng)絡(luò)玄幻小說的情感走向較之傳統(tǒng)武俠小說有何變化?
最后,在目前技術(shù)達(dá)不到的一些方面,還可做出更豐富的暢想——一款未來軟件,或未來編程語言的模塊,也能總結(jié)敘事類型,比較文本語言差異等,讓傳統(tǒng)學(xué)者的文學(xué)分析功力更有效地施展,讓計(jì)算機(jī)的研究結(jié)果和批評(píng)家的研究成果可以達(dá)成互為補(bǔ)充的效果。
那么,能否實(shí)現(xiàn)一個(gè)未來的中文文學(xué)研究軟件呢?它的可行性和可能性邊界在何方呢?事實(shí)上,除了技術(shù)的進(jìn)步,它還需要有龐大的文學(xué)語料庫資源,包含紙質(zhì)文學(xué)與網(wǎng)絡(luò)文學(xué)作品,包含紙質(zhì)出版物的文學(xué)評(píng)論與網(wǎng)友評(píng)論,在這一方面,紙質(zhì)文本高準(zhǔn)確率的數(shù)字化處理需要完成,版權(quán)也成為了某種限制。也許,全知全能型的研究軟件短期還不能實(shí)現(xiàn),或許我們也不期待它出現(xiàn)。而且,在重新審視中國文學(xué)與文論變遷上,輔助性較強(qiáng)的軟件絕對(duì)可以發(fā)揮非常重要的作用。較之于莫萊蒂的遠(yuǎn)讀法,新的細(xì)讀法仍有其價(jià)值,不過它是一種新的細(xì)讀法,不妨稱之為數(shù)字細(xì)讀法或量化細(xì)讀法,這樣的讀法在國內(nèi)剛剛起步,這樣的數(shù)據(jù)庫等待建立,而這樣一款研究軟件則充滿誘惑。


 主站蜘蛛池模板:
一本久久a久久精品vr综合|
亚洲精品国精品久久99热一|
再深点灬舒服灬太大了网站|
亚洲风情亚aⅴ在线发布|
在线精品小视频|
欧美性大战久久久久久久|
理论秋霞在线看免费|
国产麻豆天美果冻无码视频|
放荡的女老板bd中文在线观看|
久久99精品久久久久久久野外|
三级毛片在线播放|
最近高清中文在线字幕在线观看|
国产又大又硬又粗|
沦为色老头狂欲的雅婷|
国产精品自产拍在线观看|
成人自慰女黄网站免费大全|
日韩无套内射视频6|
亚洲精品www久久久久久|
亚洲免费人成在线视频观看|
精品久久久久久无码人妻蜜桃|
翁虹三级伦理电影大全在线观看|
国产综合久久久久|
亚洲乱码中文字幕综合|
抽搐一进一出在深一点|
成人片黄网站色大片免费观看app|
日本中文字幕一区二区有码在线|
色噜噜亚洲男人的天堂|
四虎影视永久在线yin56xyz|
免费扒开女人下面使劲桶|
好吊色永久免费视频大全|
日本三级午夜理伦三级三|
午夜无码A级毛片免费视频|
国产大片免费观看中文字幕|
亚洲另类自拍丝袜第五页|
一级毛片国产**永久在线|
97久久精品人妻人人搡人人玩|
好男人看的视频2018免费|
69堂在线观看|
女欢女爱第一季|
两根硕大一起挤进小h|
欧美精品一区二区三区在线|
主站蜘蛛池模板:
一本久久a久久精品vr综合|
亚洲精品国精品久久99热一|
再深点灬舒服灬太大了网站|
亚洲风情亚aⅴ在线发布|
在线精品小视频|
欧美性大战久久久久久久|
理论秋霞在线看免费|
国产麻豆天美果冻无码视频|
放荡的女老板bd中文在线观看|
久久99精品久久久久久久野外|
三级毛片在线播放|
最近高清中文在线字幕在线观看|
国产又大又硬又粗|
沦为色老头狂欲的雅婷|
国产精品自产拍在线观看|
成人自慰女黄网站免费大全|
日韩无套内射视频6|
亚洲精品www久久久久久|
亚洲免费人成在线视频观看|
精品久久久久久无码人妻蜜桃|
翁虹三级伦理电影大全在线观看|
国产综合久久久久|
亚洲乱码中文字幕综合|
抽搐一进一出在深一点|
成人片黄网站色大片免费观看app|
日本中文字幕一区二区有码在线|
色噜噜亚洲男人的天堂|
四虎影视永久在线yin56xyz|
免费扒开女人下面使劲桶|
好吊色永久免费视频大全|
日本三级午夜理伦三级三|
午夜无码A级毛片免费视频|
国产大片免费观看中文字幕|
亚洲另类自拍丝袜第五页|
一级毛片国产**永久在线|
97久久精品人妻人人搡人人玩|
好男人看的视频2018免费|
69堂在线观看|
女欢女爱第一季|
两根硕大一起挤进小h|
欧美精品一区二区三区在线|